Wealth management platforms operate in an environment where downtime is measured not just in lost revenue but in lost client trust — a currency that takes years to earn and moments to lose. For a Swiss FinTech building a regulated wealth management platform, the infrastructure question was not simply about performance or cost efficiency. It was about delivering the resilience and deployment reliability that financial services clients demand as a baseline expectation.
Propelex designed and delivered a complete high availability infrastructure and CI/CD pipeline automation solution — replacing fragile manual deployment processes with a production-grade environment built on VSphere and Rancher, with fully automated pipelines driven by TeamCity and GoCD.
About the Client
The client is a Swiss FinTech company operating in the wealth management sector — building software solutions for financial advisors, asset managers, and private banking clients. Their platform handles sensitive financial data for high-net-worth individuals and institutions, operating under Swiss financial regulation and GDPR data protection requirements.
As a regulated financial services technology provider, the client’s infrastructure reliability directly impacts their clients’ ability to serve their own end customers. Outages, deployment failures, and instability in the platform are not just internal technical problems — they are client-facing incidents with regulatory and reputational consequences. The client name is kept confidential under NDA.
The Infrastructure Challenge
Many FinTech startups build their initial infrastructure pragmatically — prioritizing speed to market over resilience, using manual deployment processes that work well enough when the team is small and releases are infrequent. As the platform matures and client expectations rise, that infrastructure becomes a liability:
- Manual deployment processes introduced human error risk — a misconfiguration during a production deployment could cause an outage affecting live client portfolios
- No high availability architecture meant a single component failure could take the entire platform offline — unacceptable for a financial services environment where clients expect continuous availability
- The absence of automated testing in the deployment pipeline meant defects could reach production without systematic validation — increasing the risk of client-facing incidents
- Development velocity was constrained by the manual deployment bottleneck — engineers could build faster than the deployment process could keep up with, creating a backlog of unreleased changes
- GDPR and Swiss financial regulation required demonstrable controls over the infrastructure environment — documentation, access controls, and audit trails that manual processes made difficult to produce consistently
Solution Architecture
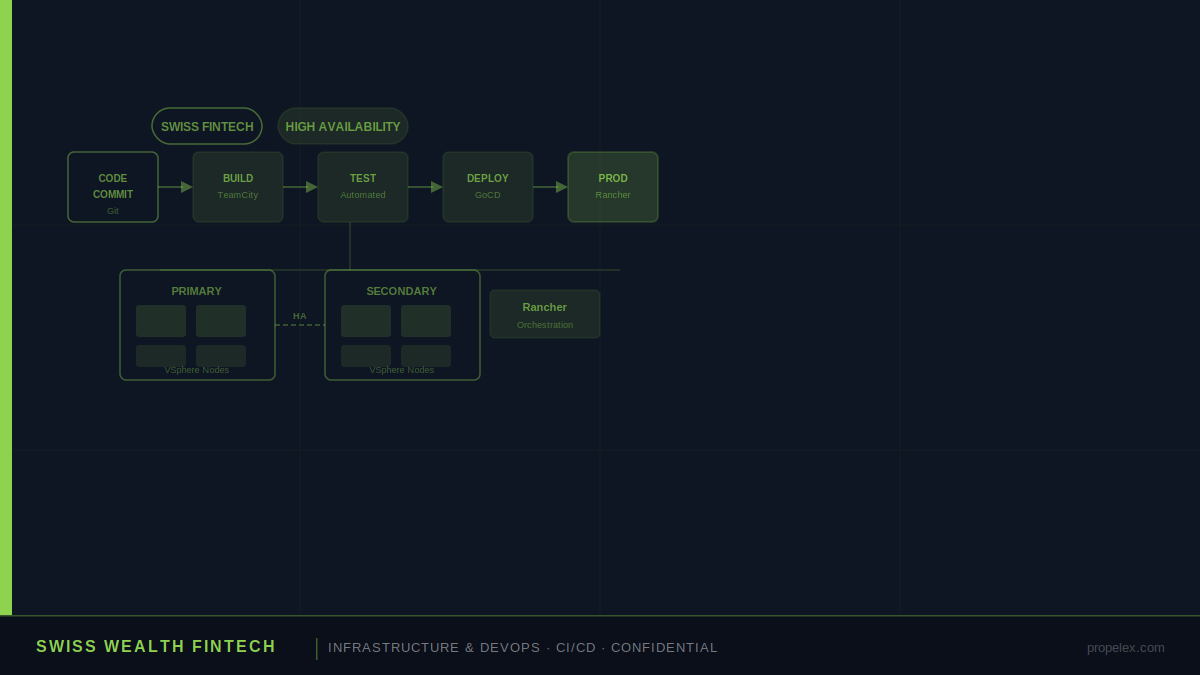
Propelex designed the solution across two interconnected layers — the high availability infrastructure layer and the CI/CD automation layer — ensuring both worked together as an integrated system rather than two separate implementations:
VSphere virtualization
VMware VSphere as the virtualization foundation — providing the hardware abstraction, resource management, and live migration capabilities needed for high availability without downtime
Rancher container orchestration
Rancher deployed on top of the VSphere layer to manage containerized workloads — providing cluster management, scaling, and deployment orchestration for the platform’s application components
TeamCity build automation
TeamCity configured as the build server — automating code compilation, dependency management, and artifact production on every commit, eliminating manual build processes entirely
GoCD deployment pipelines
GoCD configured for deployment pipeline automation — managing the flow from build artifact through testing environments to production with full visibility, approval gates, and rollback capability
High Availability Design
The HA architecture was designed to eliminate single points of failure across every layer of the infrastructure stack:
Primary and Secondary Clusters
VSphere clusters were configured in an active-active high availability arrangement — with workloads distributed across primary and secondary node sets, automatic failover configured for component failures, and live migration capability enabling maintenance without downtime. A single node failure produces automatic workload redistribution rather than a service interruption.
Rancher Orchestration Layer
Rancher manages containerized application workloads across the VSphere clusters — providing automatic scheduling, health monitoring, and restart capability for individual containers. Failed containers are automatically detected and replaced without human intervention, maintaining service continuity at the application layer independently of the infrastructure HA configuration.
CI/CD Pipeline Automation
The automated pipeline covers the complete software delivery lifecycle from code commit to production deployment:
- Commit trigger — every code commit to the Git repository automatically triggers the TeamCity build pipeline, eliminating the manual build initiation step entirely
- Automated build — TeamCity compiles the application, resolves dependencies, runs unit tests, and produces deployment artifacts — all without human intervention and with full build history and artifact versioning
- Automated testing — integration tests and validation checks run automatically as part of the pipeline, catching defects before they reach staging or production environments
- Staged deployment via GoCD — GoCD manages promotion through environments (development → staging → production) with configurable approval gates that balance automation speed with the control requirements of a regulated financial services environment
- Production deployment — approved changes deploy to the Rancher-managed production environment automatically, with rollback capability configured for immediate recovery from deployment failures
- Deployment visibility — full pipeline visibility for engineering and operations teams — every deployment is tracked, timestamped, and auditable, supporting both operational troubleshooting and compliance documentation requirements
The Results
High Availability Achieved
The VSphere and Rancher infrastructure delivers genuine high availability — automatic failover at the infrastructure layer, automatic container restart at the application layer, and live migration capability for planned maintenance. Single component failures no longer produce client-facing outages.
Manual Deployments Eliminated
The TeamCity and GoCD pipeline replaced every manual step in the deployment process — from build through test through production deployment. Engineers commit code and the pipeline handles everything that follows, with full visibility and control at each stage.
Deployment Velocity Increased
With the manual deployment bottleneck removed, the engineering team can release features and fixes as fast as they can build and test them — no longer constrained by the time and coordination required to manage manual production deployments.
Compliance Infrastructure Delivered
The automated pipeline produces complete deployment audit trails — every build, test result, and deployment is tracked and timestamped, providing the infrastructure documentation that GDPR and Swiss financial regulation require without additional manual record-keeping effort.
Key Takeaway
For FinTech platforms operating in regulated environments, infrastructure resilience and deployment reliability are not engineering nice-to-haves — they are client promises. A wealth management platform that goes down during market hours, or that deploys a defect to production because the deployment process lacked automated validation, is not just experiencing a technical failure. It is breaking a commitment to the financial advisors and institutions that depend on the platform to serve their clients.
The VSphere, Rancher, TeamCity, and GoCD stack that Propelex delivered gives this Swiss FinTech the infrastructure foundation to make those commitments confidently — with the resilience to absorb component failures without service interruption, and the pipeline automation to deliver improvements continuously without the risk that manual processes introduce.



 Infrastructure & DevOps
Infrastructure & DevOps